
22/12/2021
Création d'un connecteur Julia pour l'API météo de Meteomatics
Ou "comment j'ai appris à arrêter l'orientation objet et à aimer le dispatching multiple".

Chez Meteomatics, notre mission est de rendre notre API aussi facile à utiliser et à intégrer dans votre flux de travail que possible. Nous y parvenons notamment en fournissant des connecteurs à notre API pour toutes sortes de logiciels, y compris des programmes d'analyse de données standard tels qu'Excel et Tableau, des logiciels de systèmes d'information géographique tels qu'ArcGIS et QGIS, et bien sûr tous les langages de programmation les plus populaires.
Contrairement aux catégories de logiciels susmentionnées, qui intègrent des limites aux opérations qu'un utilisateur peut effectuer, tous les langages informatiques sont théoriquement capables de faire exactement les mêmes choses. Une question pertinente est alors : "Pourquoi se soucier d'un connecteur pour chaque langage ?". La réponse - à savoir que nos clients utilisent une variété de langages différents - n'est pas entièrement satisfaisante : pourquoi une telle variété existe-t-elle en premier lieu ?
La raison pour laquelle il existe aujourd'hui une pléthore de langages de programmation différents se résume essentiellement à deux principes : certains langages visent à rendre la lecture et l'écriture du code plus simples et plus intuitives pour les humains, accélérant ainsi le rythme auquel un nouveau code peut être développé et compris ; tandis que d'autres langages se concentrent sur la création d'instructions plus précises et donc plus efficaces pour l'ordinateur qui met en œuvre le code, réduisant ainsi les exigences en matière de temps d'exécution et de mémoire.
Ces deux principes de conception s'opposent souvent l'un à l'autre : plus il est facile pour un être humain de lire et d'écrire un code, plus son exécution sera lente et nécessitera de la mémoire, et vice versa. Néanmoins, les améliorations apportées au matériel informatique signifient que, même dans un langage interprété (1) à typage dynamique comme Python, les programmes s'exécutent beaucoup plus rapidement sur les machines modernes que les langages de bas niveau ne l'ont jamais fait sur des cartes perforées.
Depuis des décennies, les langages informatiques et leurs adeptes s'affrontent sur le champ de bataille de l'efficacité contre la lisibilité. Ces dernières années, un nouveau combattant est entré en lice, promettant de servir de médiateur entre les factions belligérantes et de nous conduire vers un avenir où la programmation informatique peut être facile à lire et à écrire, collaborative, polyvalente et efficace. Ce langage s'appelle Julia, et chez Meteomatics nous venons de publier la première version d'un connecteur Julia. Ceux qui savent déjà ce que Julia offre et qui veulent simplement se plonger dans notre nouveau connecteur peuvent se rendre directement sur GitHub. Si, en revanche, votre intérêt a été piqué et que vous voulez en savoir plus sur ce nouveau langage de programmation passionnant et sur notre implémentation, lisez la suite !
Qu'est-ce qui rend Julia si géniale ?
Bien que j'aie appris à coder en C (2), au cours de mes années de programmation en Python, j'avais oublié quelques subtilités qui définissent le fonctionnement interne de différents langages. Deux d'entre elles sont pertinentes pour discuter de Julia.
Taper et compiler
Comme je l'ai mentionné précédemment, les langages informatiques sont tous fondamentalement capables de faire les mêmes choses, car toutes les opérations informatiques sont effectuées en envoyant des instructions binaires à une unité centrale, qui est capable de transformer une chaîne de 1 et de 0 en opérations complexes (3). La différence entre un code compilé et un code interprété réside dans la manière dont le "code source" (écrit par le programmeur) est traduit en "code machine" (compris par l'unité centrale). La compilation traduit le code source en une seule fois avant d'exécuter le programme, tandis qu'un interprète traduit les instructions au fur et à mesure qu'elles sont rencontrées. Le code compilé est plus rapide car la traduction est effectuée avant l'exécution du programme. Toutefois, pour que la compilation réussisse, l'ensemble du programme doit avoir un sens, y compris les parties qui ne sont pas rencontrées. Le code interprété, en revanche, est plus lent à exécuter mais plus facile à déboguer, puisque le programme peut toujours se poursuivre jusqu'à la première instruction qui a échoué.
Julia appartient à un groupe de langages informatiques modernes qui mettent en œuvre la compilation "juste à temps" (JIT – de l'anglais "just-in-time"), qui tente de réduire la différence entre ces deux méthodes. Il est donc plus facile à déboguer que les langages compilés mais, une fois terminé, il fonctionne aussi rapidement qu'eux.
Julia est également "dynamiquement typé", ce qui signifie que les variables ne sont pas contraintes d'avoir un seul type, mais peuvent au contraire muter au cours du code. Les langages à typage statique, dans lesquels les types de variables doivent être déclarés lorsqu'une variable est initialisée, détectent une grande partie des erreurs de manière précoce (souvent à la compilation plutôt qu'à l'exécution), ce qui facilite légèrement la collaboration sur le code, puisque le format des variables renvoyées par les fonctions est toujours explicite. L'avantage du typage dynamique réside essentiellement dans le fait que le code est plus indulgent pour le programmeur, bien que des erreurs inattendues puissent parfois apparaître en cours de route et qu'il soit difficile de remonter à la source.
Ensemble, le typage dynamique et la compilation JIT de Julia sont conçus pour rendre le langage relativement facile à apprendre et intuitif à écrire. Ces principes devraient cependant être familiers à toute personne ayant déjà écrit du code Python. De plus, Python bénéficie de nombreuses années de développement et, par conséquent, d'un grand nombre de bibliothèques permettant d'effectuer toutes sortes de tâches, dont certaines doivent encore être développées pour Julia. Alors, je vous entends demander : pourquoi se donner la peine ?
Répartition multiple
La caractéristique principale de Julia qui la distingue de la plupart des autres langages est son "paradigme de distribution multiple". Cette caractéristique, qui est relativement facile à décrire, finit par avoir un certain nombre d'effets en chaîne pour Julia qui sont hautement souhaitables.
La répartition multiple signifie essentiellement que les fonctions sont définies plusieurs fois dans Julia en fonction des types de variables qu'elles prennent. Un petit exemple illustre l'idée générale (4). Tout d'abord, nous créons deux nouveaux types de données - Cat et Dog - qui sont tous deux des Pets.
` abstract type Pet end struct Cat <: Pet name::String end struct Dog <: Pet name::String end function encounter(a::Pet, b::Pet) action = meets(a, b) println(“$a.name $action $b.name”) end `
Un type abstrait est différent d'un type concret (struct) en ce sens que des instances de ce type ne peuvent pas être créées. Il est utile de placer des types dans une hiérarchie de types, ce qui à son tour est utile pour définir un comportement de secours, comme nous le verrons. Pour résumer brièvement le reste de la syntaxe ci-dessus : <: signifie que le type de gauche est un sous-type immédiat du type de droite; :: signifie que la variable a ce type, c'est-à-dire que le champ "nom" de nos Pets doit être une chaîne de caractères; Julia utilise end pour terminer les blocs de code, plutôt que le tabulation comme en Python (bien qu'il n'y ait aucune règle contre la tabulation et je l'inclus pour faciliter la lisibilité); et les chaînes de caractères en Julia sont encadrées par ”, et le symbole $ est utilisé pour l'interpolation de chaînes de caractères.
La fonction définie ci-dessus imprimera une chaîne de caractères indiquant ce qui se passe lorsque `a` rencontre `b`, à condition que `a` et `b` soient tous deux des Pets. La pièce manquante du puzzle est la fonction `meets`, que nous allons maintenant définir.
function meets(a::Dog, b::Dog) = “sniffs” function meets(a::Dog, b::Cat) = “chases” function meets(a::Cat, b::Dog) = “runs away from” function meets(a::Cat, b::Cat) = “hisses at” `
Cette fonction a été définie quatre fois, mais nous n'avons écrasé aucune des définitions précédentes. Chaque définition est appelée "méthode" de la fonction, et la méthode utilisée au moment de l'exécution dépend des types des variables transmises. Créons quelques Pets et voyons comment notre code se comporte :
` clifford = Dog(“Clifford”) fenton = Dog(“Fenton”) felix = Cat(“Felix”) sylvester = Cat(“Sylvester”) encounter(clifford, sylvester)
>>> Clifford chases Sylvester
encounter(felix, fenton)
>>> Felix runs away from Fenton
encounter(fenton, clifford)
>>> Fenton sniffs Clifford
encounter(sylvester, felix)
>>> Sylvester hisses at Felix
`
Nous pouvons donc voir comment les types de données de nos variables affectent l'exécution d'une fonction qui porte le même nom à chaque fois qu'elle est appelée. Nous avons déjà utilisé le supertype Pet pour nous assurer qu'une erreur de type est levée si les types passés à `encounter` ne sont pas des Pets, c'est-à-dire
` encounter(“Felix”, “Clifford”) >>> ERROR: MethodError: no method matching encounter(::String, ::String) `
mais nous pouvons aussi l'utiliser pour implémenter une méthode plus générique pour `meets` :
` meets(a::Pet, b::Pet) = “stares cautiously at” struct Rabbit <: Pet; name::String end fiver = Rabbit(“Fiver”) encounter(fiver, sylvester) >>> Fiver stares cautiously at Sylvester `
Cet exemple démontre succinctement l'implémentation de la distribution multiple dans Julia, mais pourquoi est-elle utile ? Il y a trois conséquences principales de ce paradigme qui commencent à attirer des convertis d'autres langages.
Réutilisation du code
Le fait que les différentes méthodes d'une fonction Julia soient toutes nommées de manière identique, combiné à l'approche dynamique du typage du langage, signifie que, lors de l'écriture du code, nous n'avons pas besoin de penser trop fort aux types de nos variables. En Python, pour obtenir les mêmes résultats que dans l'exemple ci-dessus, il faudrait soit définir la fonction `meets` comme une méthode sur les objets Cat/Dog (5), soit définir plusieurs fonctions avec des noms non identiques (par exemple `cat_meets_dog()` ; `dog_meets_dog()`).
Le problème de cette dernière approche est clair : l'utilisateur doit se souvenir de la fonction requise pour chaque ensemble de types d'entrée. Les limites de la première approche sont que les méthodes sont liées à l'objet : la méthode ne peut être utilisée que si une instance de l'objet existe, elle ne peut être utilisée que sur l'objet donné et ne peut pas être facilement étendue pour couvrir de nouveaux comportements d'objets nouveaux ou mis à jour. Ces deux problèmes augmentent avec le nombre de variables d'entrée de la fonction - dans notre exemple, il n'y a que deux variables pour chaque méthode, mais ce n'est pas forcément le cas : il n'y a pas de limite au nombre d'arguments sur lesquels les méthodes Julia peuvent être "distribuées", et les différentes méthodes d'une même fonction ne doivent pas nécessairement prendre le même nombre d'arguments.
Aussi abstrait que cela puisse paraître, il y a un avantage pratique à construire un code avec des fonctions génériques non liées : il est incroyablement facile de réutiliser le code ! Définissez une fonction - ou étendez une fonction existante - pour gérer un nouveau type de données, et tout ce que vous devez faire pour l'utiliser à l'avenir est de l'importer. Julia étant un langage relativement nouveau, certaines opérations auxquelles vous étiez habitué dans votre langage précédent peuvent ne pas avoir été implémentées, mais vous n'avez besoin de les implémenter vous-même qu'une seule fois (6).
Compatibilité des paquets
Un résultat peut-être pas évident de cette facilité de réutilisation du code est que des méthodes/types de données bien définis se propagent également dans le code d'autres personnes ! Comme les noms des fonctions appelées ne changent jamais, les paquets interagissent de manière transparente sans avoir été spécifiquement conçus pour cela. Un exemple souvent cité est la compatibilité des paquets DifferentialEquations et Measurements. Le premier fournit une boîte à outils pour la résolution d'équations différentielles de toutes sortes ; le second permet aux utilisateurs d'ajouter de l'incertitude à leurs données. La magie de Julia réside dans le fait qu'en insérant les types de données de Measurements dans les fonctions de résolution de DifferentialEquations, nous pouvons obtenir une solution qui propage correctement l'erreur !
Efficacité
L'avantage le plus cité de Julia par rapport à Python est peut-être son efficacité relative. Julia peut fonctionner jusqu'à 10 fois plus vite que Python, ce qui n'est peut-être pas très important pour un code simple qui s'exécute en quelques secondes, mais qui peut s'étendre rapidement si l'on considère, par exemple, un code numérique complexe de prédiction météorologique qui peut facilement prendre des jours. Une partie de cette efficacité provient de la compilation JIT de Julia, mais un autre facteur est l'exploitation de la répartition multiple pour l'efficacité.
Un bon exemple pour ceux qui sont familiers avec l'algèbre linéaire est celui du "one-hot vector". Un vecteur à un coup est un vecteur qui est uniformément 0 à l'exception d'un index, qui contient un 1. Sans entrer dans les détails de la multiplication matricielle, cela signifie qu'un produit intérieur du vecteur à un coup V avec la matrice où M est

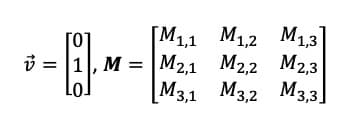
is

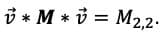
Ce résultat peut être immédiatement obtenu à partir de la connaissance de l'indice où

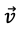
est non nul, et est beaucoup plus rapide que de suivre le processus compliqué de multiplication des matrices à travers toutes ses étapes fastidieuses.
Dans Julia, cela peut être facilement réalisé en créant une structure pour le vecteur à un coup (7) et en étendant les méthodes de produit intérieur à ce nouveau type de données. Les mathématiciens devraient pouvoir penser à de nombreux exemples de raccourcis de cas spéciaux qu'ils ont rencontrés dans leurs études et qui pourraient être codés de cette manière ; le domaine de l'algèbre linéaire en est truffé, faisant de Julia un langage extrêmement puissant pour traiter efficacement les matrices, avec des implications pour tous les domaines - tels que l'apprentissage automatique en vogue - qui en ont besoin. L'exemple ci-dessus pourrait impliquer que, pour utiliser Julia avec une efficacité optimale, les utilisateurs devraient reconnaître les opportunités d'implémenter ces raccourcis, mais en fait, même les opérations arithmétiques de bas niveau ont différentes méthodes intégrées pour distribuer sur les types de base tels que Integer vs Float, et beaucoup d'autres implémentations d'accélération sont incluses dans les paquets populaires.
Notre connecteur
L'utilisation la plus évidente du système de distribution multiple dans notre connecteur Julia est le changement de casse impliqué par diverses méthodes des fonctions de requête. Plutôt que d'envoyer des erreurs lorsqu'un utilisateur fournit une chaîne de caractères date/heure à une fonction, par exemple, le module ParserFunctions définit plusieurs méthodes pour traiter différentes entrées. Cette conception se prête davantage à une facilité d'utilisation et à une compatibilité accrues qu'à une efficacité accrue de l'envoi multiple, mais elle est néanmoins utile.
Il faut faire attention au moment et à l'endroit où l'on utilise l'envoi multiple. Dans notre connecteur, une seule fonction `query` aurait pu être écrite pour renvoyer différents résultats en fonction des paramètres d'entrée - une série temporelle si des plages et des intervalles de dates et d'heures étaient fournis ; une grille si une seule date/heure était donnée pour délimiter les latitudes et les longitudes. Cependant, j'ai décidé, et je pense que c'est un bon principe directeur pour écrire Julia, de séparer les fonctions si l'utilisateur s'attend à des résultats différents lorsqu'il les appelle - ainsi, le résultat souhaité est impliqué par le nom de la fonction, plutôt que par la combinaison des arguments.
Je définis deux structures personnalisées dans le module DataTypes qui peuvent facilement être étendues pour couvrir une gamme plus large de requêtes, que nous souhaitons développer dans les mois à venir. Il convient de noter que les requêtes actuellement implémentées a) demandent toutes leurs données sous la forme de .csvs, ce qui n'est pas une manière particulièrement efficace d'obtenir des données du serveur mais qui fonctionne et b) renvoient toutes les données à l'utilisateur sous la forme de Julia DataFrames qui, bien qu'elles ne disposent pas de certaines des fonctionnalités des Python Pandas DataFrames, peuvent facilement être transformées en d'autres structures de données Julia.
Dans cet article, j'espère avoir fourni une introduction simple à certaines des caractéristiques intéressantes de ce nouveau langage de programmation en vogue, ainsi qu'un code de connecteur API qui est lisible, utilisable et extensible. Essayez-le, et faites-moi savoir si vous cassez quelque chose ! Je peux maintenant dire honnêtement que, même s'il me faudra un certain temps pour m'habituer complètement à la syntaxe de Julia, je suis enthousiasmé par certaines des possibilités qu'il offre aux développeurs, et chaque fois que j'écris du Python maintenant, je me surprends souvent à penser "ce serait beaucoup plus joli en Julia". Quant à l'objectif de Julia d'unifier tous les langages de programmation dans une interface intuitive et efficace, eh bien, seul le temps nous le dira.
Coda: “Je n'aime pas le changement”
Le connecteur Python pour l'API Meteomatics reste le connecteur le mieux développé que nous ayons à notre disposition, et les utilisateurs familiers avec lui peuvent être initialement frustrés par les limitations de notre connecteur Julia actuel. Heureusement, Julia reconnaît que les convertis d'autres langages auront des paquets/modules qu'ils aiment et dont ils ne peuvent se passer, et fournit donc un moyen de les inclure. Si vous voulez jouer avec certaines des nouvelles fonctionnalités de Julia mais que vous voulez aussi utiliser toute la syntaxe qui vous est familière avec notre connecteur Python, vous pouvez suivre les étapes suivantes :
- En utilisant le mode gestionnaire de paquets:
- Dans une REPL Julia, tapez `]` pour entrer dans le mode gestionnaire de paquets
- Tapez `add PyCall`
- Alternativement:
- Importez le module gestionnaire de paquets en tapant `utilisant Pkg`/li>
- Tapez `Pkg.add("PyCall")`
.
- N'utilisez pas les environnements virtuels Anaconda, car ils ne sont pas pris en charge par PyCall
.
- `ENV["PYTHON"]="path/to/directory/containing/environment/python/executable"`
`Pkg.build("PyCall")` - Redémarrer la REPL
- `using PyCall`
`mm = pyimport(“meteomatics.api”)`
Cette méthode peut bien sûr être utilisée pour importer d'autres modules de Python, et des packages similaires existent pour d'autres langages également, alors n'ayez pas peur de vous habituer à un paradigme de distribution multiple tout en travaillant avec un code prévisible avec lequel vous êtes intimement familier !
Si vous avez des questions ou des commentaires sur cet article ou sur Julia en général, vous pouvez toujours me contacter en écrivant à [email protected] - j'ai hâte de discuter avec vous!
- Techniquement, "interprété" vs "compilé" est une caractéristique de l'implémentation, pas du langage, mais Python est certainement typiquement implémenté à travers un interpréteur.)
- "Le latin des langages informatiques" : un langage mort que personne n'utilise plus mais qui introduit néanmoins les étudiants à toutes les caractéristiques importantes d'un langage, et qui est la base de beaucoup de langages modernes.
- Si vous souhaitez explorer cette merveille en profondeur, je vous recommande vivement le cours nand2tetris, qui montre comment de simples portes logiques peuvent être combinées pour créer un ordinateur entièrement fonctionnel. Le jeu Steam Turing Complete promet également d'atteindre un objectif similaire.
- Je suis de près l'exemple donné dans le cours Zero2Hero de George Datseris, dont le reste peut intéresser ceux qui souhaitent une introduction plus complète à Julia
- Dans la plupart des langages "orientés objet", un "objet" est une structure qui contient des champs/attributs (variables définies par rapport à l'objet) et des procédures/méthodes (fonctions définies par rapport à l'objet).
- Je recommande de conserver un module dédié d'opérations/extensions que vous pouvez importer chaque fois que vous écrivez Julia afin qu'elle se comporte comme vous le souhaitez sans avoir à y penser.
- Qui peut lui-même être efficacement représenté par deux nombres : une longueur (du vecteur) et un index (lorsqu'il n'est pas nul).

Parlez à un expert








