
22.12.2021
Erstellen eines Julia-Konnektors für die Wetter-API von Meteomatics
Oder "Wie ich lernte, mit der Objektorientierung aufzuhören und die Mehrfachabfertigung zu lieben".

Wir bei Meteomatics haben es uns zur Aufgabe gemacht, dass unsere API so einfach wie möglich zu nutzen ist und Sie sie einfach in Ihren Workflow integrieren können. Dies erreichen wir unter anderem dadurch, dass wir Konnektoren zu unserer API für alle Arten von Software bereitstellen, darunter Standard-Datenanalyseprogramme wie Excel und Tableau, Software für geografische Informationssysteme wie ArcGIS und QGIS und natürlich alle gängigen Programmiersprachen.
Im Gegensatz zu den vorher genannten Softwarekategorien, bei denen die vom Benutzer durchzuführenden Operationen programmtechnisch begrenzt sind, sind alle Computersprachen theoretisch in der Lage, genau dieselben Dinge zu tun. Eine wichtige Frage ist daher: "Warum sollte man sich die Mühe machen, für jede Sprache einen Konnektor zu entwickeln?". Die Antwort - dass unsere Kunden eine Vielzahl verschiedener Sprachen verwenden - ist nicht sehr befriedigend: Warum gibt es überhaupt eine solche Vielfalt?
Die Gründe dafür, dass es heute eine Vielzahl verschiedener Programmiersprachen gibt, lassen sich im Wesentlichen auf zwei Prinzipien zurückführen: Einige Sprachen zielen darauf ab, das Lesen und Schreiben von Code für Menschen einfacher und intuitiver zu machen und damit die Entwicklung und das Verständnis von neuem Code zu beschleunigen; andere Sprachen wiederum konzentrieren sich darauf, präzisere und damit effizientere Anweisungen für den Computer zu erstellen, der den Code implementiert, und damit die Laufzeit und den Speicherbedarf zu reduzieren.
Diese beiden Designprinzipien stehen oft im Widerspruch zueinander - je einfacher es für einen Menschen ist, den Code zu lesen und zu schreiben, desto langsamer und speicherintensiver wird er in der Regel ausgeführt, und umgekehrt. Dennoch bedeuten die Verbesserungen in der Computer-Hardware, dass selbst in einer dynamisch typisierten, interpretierten (1) Sprache wie Python Programme auf modernen Maschinen viel schneller laufen als Low-Level-Sprachen jemals auf Lochkarten.
Seit Jahrzehnten kämpfen die Computersprachen und ihre Anhänger auf dem Schlachtfeld zwischen Effizienz und Lesbarkeit. In den letzten Jahren hat sich ein neuer Kämpfer in den Kampf eingeschaltet, der verspricht, zwischen den streitenden Parteien zu vermitteln und uns in eine Zukunft zu führen, in der Computerprogrammierung einfach zu lesen und zu schreiben, kollaborativ, vielseitig und effizient sein kann. Diese Sprache heisst Julia, und bei Meteomatics haben wir gerade die erste Version eines Julia-Konnektors veröffentlicht. Diejenigen, die bereits wissen was Julia zu bieten hat und sich mit unserem neuen Konnektor vertraut machen wollen, können direkt zu GitHub gehen. Wenn Ihr Interesse geweckt ist und Sie mehr über diese aufregende neue Programmiersprache und unsere Implementierung erfahren möchten, lesen Sie weiter!
Was macht Julia so grossartig?
Obwohl ich in C programmieren gelernt habe (2), habe ich in den Jahren, in denen ich Python programmiert habe, einige Feinheiten vergessen, die die interne Funktionsweise verschiedener Sprachen bestimmen. Zwei davon sind für die Diskussion über Julia relevant.
Tippen und Kompilieren
Der Schlüssel dazu, warum, wie ich bereits erwähnt habe, alle Computersprachen grundsätzlich das Gleiche können, liegt darin, dass alle Computeroperationen durch das Senden von Binärbefehlen an eine CPU ausgeführt werden, die in der Lage ist, eine Folge von 1en und 0en in komplexe Operationen umzuwandeln (3). Der Unterschied zwischen einem kompilierten und einem interpretierten Code besteht darin, wie der (vom Programmierer geschriebene) "Quellcode" in "Maschinencode" (der von der CPU verstanden wird) übersetzt wird. Bei der Kompilierung wird der gesamte Quellcode auf einmal übersetzt, bevor das Programm ausgeführt wird, während ein Interpreter die Anweisungen übersetzt, sobald sie auftauchen. Kompilierter Code ist schneller, da die Übersetzung vor der Laufzeit erfolgt. Um jedoch erfolgreich zu kompilieren, muss das gesamte Programm einen Sinn ergeben, einschliesslich der Bits, die nicht angetroffen werden. Interpretierter Code hingegen ist langsamer, aber leichter zu debuggen, da das Programm immer bis zur ersten fehlgeschlagenen Anweisung weiterlaufen kann.
Julia gehört zu einer Gruppe moderner Computersprachen, die eine "Just-in-Time"-Kompilierung (JIT) durchführen, die versucht, den Unterschied zwischen diesen beiden Methoden aufzulösen. Sie ist daher einfacher zu debuggen als kompilierte Sprachen, läuft aber, wenn sie fertig ist, genauso schnell wie diese.
Julia ist ausserdem "dynamisch typisiert", was bedeutet, dass Variablen nicht auf einen einzigen Typ beschränkt sind, sondern sich während des Codeflusses ändern können. Statisch typisierte" Sprachen, bei denen die Variablentypen bei der Initialisierung einer Variable deklariert werden müssen, fangen viele Fehler schon früh ab (oft bei der Kompilierung und nicht zur Laufzeit), was die Zusammenarbeit am Code etwas erleichtert, da das Format der von Funktionen zurückgegebenen Variablen immer eindeutig ist. Der Vorteil der dynamischen Typisierung besteht im Wesentlichen darin, dass der Code dem Programmierer mehr verzeiht, auch wenn unerwartete Fehler manchmal erst im Nachhinein auftauchen und nur schwer auf eine Quelle zurückgeführt werden können.
Zusammengenommen sind die dynamische Typisierung und die JIT-Kompilierung von Julia so konzipiert, dass die Sprache relativ leicht zu erlernen und intuitiv zu schreiben ist. Diese Prinzipien sollten jedoch jedem bekannt sein, der schon einmal Python-Code geschrieben hat. Ausserdem hat Python den Vorteil, dass es seit vielen Jahren entwickelt wird und daher eine grosse Anzahl von Bibliotheken für alle möglichen Aufgaben zur Verfügung steht, von denen einige für Julia erst noch entwickelt werden müssen. Sie werden sich also fragen, warum sich die Mühe machen?
Mehrfacher Dispatch
Das entscheidende Merkmal von Julia, das es von den meisten anderen Sprachen unterscheidet, ist das "multiple dispatch paradigm". Diese relativ einfach zu beschreibende Eigenschaft hat eine Reihe von Auswirkungen auf Julia, die sehr erwünscht sind.
Multiple Dispatch bedeutet im Wesentlichen, dass Funktionen in Julia mehrfach definiert werden, abhängig von den Typen der Variablen, die sie annehmen. Ein kleines Beispiel verdeutlicht die allgemeine Idee (4). Zunächst erstellen wir zwei neue Datentypen - Katze und Hund -, die beide Haustiere sind.
` abstract type Pet end struct Cat <: Pet name::String end struct Dog <: Pet name::String end function encounter(a::Pet, b::Pet) action = meets(a, b) println(“$a.name $action $b.name”) end `
Ein abstrakter Typ unterscheidet sich von einem konkreten Typ (struct) dadurch, dass keine Instanzen von ihm erzeugt werden können. Er ist nützlich, um Typen in einem Typbaum zu platzieren, was wiederum nützlich ist, um Fallback-Verhalten zu definieren, wie wir noch sehen werden. Um den Rest der Syntax in der obigen Tabelle kurz zusammenzufassen: `<:` bedeutet, dass der linke Typ ein unmittelbarer Subtyp des rechten Typs ist; `::` bedeutet, dass die Variable diesen Typ hat, d.h. das Feld 'name' unserer Haustiere muss ein String sein; Julia verwendet `end`, um Codeblöcke zu beenden, anstatt Tabulatoren wie in Python zu verwenden (obwohl es keine Regel gegen Tabulatoren gibt und ich sie aus Gründen der Lesbarkeit einfüge); und Strings werden in Julia von `"` umschlossen, und das Symbol `$` wird für die String-Interpolation verwendet.
Die oben definierte Funktion gibt einen String aus, der angibt, was passiert, wenn `a` auf `b` trifft, vorausgesetzt `a` und `b` sind beide Pets. Das fehlende Teil des Puzzles ist die Funktion `meets`, die wir nun definieren werden.
function meets(a::Dog, b::Dog) = “sniffs” function meets(a::Dog, b::Cat) = “chases” function meets(a::Cat, b::Dog) = “runs away from” function meets(a::Cat, b::Cat) = “hisses at” `
Diese Funktion wurde bereits viermal definiert, aber wir haben keine der früheren Definitionen überschrieben. Jede Definition wird als "Methode" der Funktion bezeichnet, und welche Methode zur Laufzeit verwendet wird, hängt von den Typen der übergebenen Variablen ab. Lassen Sie uns einige Pets erstellen und sehen, wie sich unser Code verhält:
` clifford = Dog(“Clifford”) fenton = Dog(“Fenton”) felix = Cat(“Felix”) sylvester = Cat(“Sylvester”) encounter(clifford, sylvester)
>>> Clifford chases Sylvester
encounter(felix, fenton)
>>> Felix runs away from Fenton
encounter(fenton, clifford)
>>> Fenton sniffs Clifford
encounter(sylvester, felix)
>>> Sylvester hisses at Felix
`
So können wir sehen, wie sich die Datentypen unserer Variablen auf die Ausführung einer Funktion auswirken, die bei jedem Aufruf denselben Namen hat. Wir haben bereits den Supertyp Pet verwendet, um sicherzustellen, dass ein Typfehler ausgelöst wird, wenn die an `encounter` übergebenen Typen nicht Pets sind, d.h.
` encounter(“Felix”, “Clifford”) >>> ERROR: MethodError: no method matching encounter(::String, ::String) `
aber wir können es auch verwenden, um eine allgemeinere Methode für `meets` zu implementieren:
` meets(a::Pet, b::Pet) = “stares cautiously at” struct Rabbit <: Pet; name::String end fiver = Rabbit(“Fiver”) encounter(fiver, sylvester) >>> Fiver stares cautiously at Sylvester `
Dieses Beispiel demonstriert kurz und bündig die Implementierung von Multiple Dispatch in Julia, aber warum ist es nützlich? Es gibt drei Hauptkonsequenzen dieses Paradigmas, die allmählich Konvertiten aus anderen Sprachen anziehen.
Wiederverwendung von Code
Die Tatsache, dass die verschiedenen Methoden einer Julia-Funktion alle identisch benannt sind, in Kombination mit dem dynamischen Ansatz der Sprache bei der Typisierung, bedeutet, dass wir beim Schreiben von Code nicht allzu viel über die Typen unserer Variablen nachdenken müssen. Um in Python die gleichen Ergebnisse wie in unserem obigen Beispiel zu erzielen, müssten wir entweder die Funktion `meets` als Methode für Cat/Dog-Objekte (5) definieren oder mehrere Funktionen mit nicht identischen Namen (z.B. `cat_meets_dog()`; `dog_meets_dog()`) definieren.
Das Problem des letztgenannten Ansatzes liegt auf der Hand: Der Benutzer muss sich für jeden Satz von Eingabetypen die erforderliche Funktion merken. Die bisherigen Einschränkungen des ersten Ansatzes bestehen darin, dass die Methoden an das Objekt gebunden sind: Die Methode kann nur verwendet werden, wenn eine Instanz des Objekts existiert, kann nur auf das gegebene Objekt angewendet werden und kann nicht einfach erweitert werden, um das Verhalten neuer/aktualisierter Objekte abzudecken. Beide Probleme skalieren mit der Anzahl der Eingangsvariablen für die Funktion - in unserem Beispiel gibt es nur zwei Variablen für jede Methode, aber das muss nicht der Fall sein: Es gibt keine Begrenzung für die Anzahl der Argumente, auf die Julia-Methoden "abgefertigt" werden können, und verschiedene Methoden derselben Funktion müssen nicht einmal unbedingt die gleiche Anzahl von Argumenten annehmen.
So abstrakt das auch klingt, es gibt einen praktischen Vorteil beim Erstellen von Code mit ungebundenen generischen Funktionen: Es ist unglaublich einfach, Code wiederzuverwenden! Definieren Sie eine Funktion - oder erweitern Sie eine bestehende -, um einen neuen Datentyp zu verarbeiten, und alles, was Sie tun müssen, um sie in Zukunft zu verwenden, ist sie zu importieren. Da es sich bei Julia um eine relativ neue Sprache handelt, sind einige Operationen, die Sie vielleicht aus Ihrer vorherigen Sprache gewohnt sind, noch nicht implementiert, aber Sie müssen sie nur einmal selbst implementieren (6).
Paket-Kompatibilität
Eine vielleicht nicht ganz offensichtliche Folge dieser einfachen Wiederverwendung von Code ist, dass sich gut definierte Methoden/Datentypen auch im Code anderer Leute ausbreiten! Da sich die Namen der aufgerufenen Funktionen nie ändern, können Pakete nahtlos zusammenarbeiten, ohne dass sie jemals speziell dafür entwickelt wurden. Ein häufig zitiertes Beispiel dafür ist die Kompatibilität der Pakete DifferentialEquations und Measurements. Ersteres bietet ein Toolkit zum Lösen von Differentialgleichungen aller Art; letzteres ermöglicht es den Benutzern, ihren Daten Unsicherheiten hinzuzufügen. Die Magie von Julia besteht darin, dass wir durch das Einfügen von Datentypen aus Measurements in Solver-Funktionen aus DifferentialEquations eine Lösung erhalten, die Fehler korrekt weitergibt!
Effizienz
Der vielleicht am häufigsten zitierte Vorteil von Julia gegenüber Python ist seine relative Effizienz. Julia kann bis zu 10-mal schneller laufen als Python, was bei einfachem Code, der nur Sekunden braucht, vielleicht nicht so wichtig ist, aber bei komplexem numerischen Wettervorhersagecode, der leicht Tage dauern kann, schnell ins Gewicht fällt. Ein Teil dieser Effizienz kommt von der JIT-Kompilierung von Julia, aber ein weiterer Faktor ist die Nutzung von Multiple Dispatch zur Steigerung der Effizienz.
Ein gutes Beispiel für diejenigen, die mit linearer Algebra vertraut sind, ist der "One-Hot-Vektor". Ein One-Hot-Vektor ist ein Vektor, der bis auf einen Index, der eine 1 enthält, einheitlich 0 ist. Ohne auf die Besonderheiten der Matrixmultiplikation einzugehen, bedeutet dies, dass ein inneres Produkt des One-Hot-Vektors V mit der Matrix, in der M ist

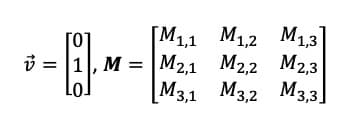
ist

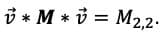
Dieses Ergebnis lässt sich unmittelbar aus der Kenntnis des Index ableiten, wobei

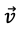
ungleich Null ist, und ist viel schneller als der komplizierte Prozess der Multiplikation von Matrizen mit all seinen langwierigen Schritten.
In Julia kann dies leicht erreicht werden, indem man eine Struktur für den One-Hot-Vektor (7) erstellt und die Methoden des inneren Produkts für diesen neuen Datentyp erweitert. Dem mathematisch interessierten Leser dürften zahlreiche Beispiele für Sonderfälle einfallen, denen er in seinem Studium begegnet ist und die sich auf diese Weise kodieren liessen; die lineare Algebra ist voll davon, was Julia zu einer äusserst leistungsfähigen Sprache für die effiziente Verarbeitung von Matrizen macht, mit Auswirkungen auf alle Bereiche, die dies erfordern, wie etwa das in Mode gekommene maschinelle Lernen. Das obige Beispiel könnte den Eindruck erwecken, dass der Benutzer, um Julia mit optimaler Effizienz zu nutzen, Möglichkeiten erkennen müsste, diese Abkürzungen zu implementieren, aber in der Tat haben sogar arithmetische Operationen auf niedriger Ebene verschiedene eingebaute Methoden, um auf Grundtypen wie Integer vs. Float zu reagieren, und viele andere Implementierungen zur Beschleunigung sind in beliebten Paketen enthalten.
Unser Konnektor
Die auffälligste Anwendung des Multiple-Dispatch-Systems in unserem Julia-Konnektor ist die Umschaltung zwischen Gross- und Kleinschreibung, die durch verschiedene Methoden der Abfragefunktionen impliziert wird. Anstatt Fehlermeldungen auszugeben, wenn ein Benutzer z.B. eine Datums-/Zeit-Zeichenkette an eine Funktion übergibt, definiert das ParserFunctions-Modul mehrere Methoden zur Behandlung verschiedener Eingaben. Dieses Design dient mehr der Benutzerfreundlichkeit/Kompatibilität als der Effizienzsteigerung durch mehrfaches Dispatching, ist aber dennoch nützlich.
Man muss vorsichtig sein, wann und wo man die Mehrfachabfertigung verwendet. In unserem Konnektor hätte man eine einzige "Abfrage"-Funktion schreiben können, die je nach den Eingabeparametern unterschiedliche Ergebnisse liefert - eine Zeitreihe, wenn Datums-/Zeitbereiche und Intervalle angegeben wurden; ein Raster, wenn ein einziges Datum/eine einzige Zeit für die Begrenzung von Breiten- und Längengraden angegeben wurde. Ich habe mich jedoch entschieden, und ich denke, das ist ein guter Leitsatz für das Schreiben von Julia, die Funktionen zu trennen, wenn der Benutzer unterschiedliche Ergebnisse erwartet, wenn er sie aufruft - daher wird das gewünschte Ergebnis durch den Funktionsnamen impliziert und nicht durch die Kombination der Argumente.
Im Modul DataTypes habe ich zwei benutzerdefinierte Strukturen definiert, die leicht erweitert werden können, um eine grössere Anzahl von Abfragen abzudecken, was wir in den kommenden Monaten entwickeln wollen. Es ist anzumerken, dass die derzeit implementierten Abfragen a) alle Daten in Form von .csvs anfordern, was keine besonders effiziente Art ist, Daten vom Server zu erhalten, aber funktioniert, und b) alle Daten in Form von Julia DataFrames an den Benutzer zurückgeben, die zwar einige der Feinheiten von Python Pandas DataFrames vermissen lassen, aber leicht in andere Julia-Datenstrukturen transformiert werden können.
In diesem Artikel habe ich hoffentlich eine einfache Einführung in einige der interessanten Funktionen dieser heissen neuen Programmiersprache gegeben und auch API-Connector-Code bereitgestellt, der lesbar, verwendbar und erweiterbar ist. Probieren Sie es aus, und lassen Sie mich wissen, wenn Sie etwas kaputt machen! Ich kann jetzt ehrlich sagen, dass ich zwar eine Weile brauchen werde, um mich vollständig an die Syntax von Julia zu gewöhnen, aber ich bin begeistert von den Möglichkeiten, die sie Entwicklern bietet, und wenn ich jetzt Python schreibe, denke ich oft: "Das wäre in Julia viel schöner". Was das Ziel von Julia angeht, alle Programmiersprachen in einer intuitiven, effizienten Oberfläche zu vereinen, so wird sich das erst mit der Zeit zeigen.
Coda: "Ich mag keine Veränderungen"
Der Python-Konnektor für die Meteomatics-API ist nach wie vor der am besten entwickelte Konnektor, den wir zur Verfügung haben, und Benutzer, die damit vertraut sind, könnten anfangs von den Einschränkungen unseres aktuellen Julia-Konnektors frustriert sein. Glücklicherweise erkennt Julia, dass Konvertierer aus anderen Sprachen Pakete/Module haben, die sie lieben und ohne die sie nicht auskommen können, und bietet daher eine Möglichkeit, diese einzubinden. Wenn Sie einige der neuen Funktionen von Julia ausprobieren, aber auch die Syntax verwenden möchten, die Ihnen von unserem Python-Konnektor vertraut ist, können Sie die folgenden Schritte ausführen:
- Verwendung des Paketverwaltungsmodus:
- Geben Sie in einer Julia-REPL `]` ein, um den Paketverwaltungsmodus aufzurufen
- Geben Sie `add PyCall` ein
- Alternativ dazu:
- Importieren Sie das Paketverwaltungsmodul durch Eingabe von `Pkg`.
- Geben Sie `Pkg.add("PyCall")` ein
- Verwenden Sie keine virtuellen Umgebungen von Anaconda, da diese von PyCall nicht unterstützt werden.
- `ENV[“PYTHON”]=“path/to/directory/containing/environment/python/executable”`
`Pkg.build(“PyCall”)` - Starten Sie die REPL neu
- `using PyCall`
`mm = pyimport(“meteomatics.api”)`
Diese Methode kann natürlich auch verwendet werden, um andere Module aus Python zu importieren, und ähnliche Pakete gibt es auch für andere Sprachen. Haben Sie also keine Angst, sich an das Paradigma des Multiple Dispatch zu gewöhnen, während Sie mit vorhersehbarem Code arbeiten, mit dem Sie bestens vertraut sind!
Wenn Sie Fragen oder Kommentare zu diesem Artikel oder zu Julia im Allgemeinen haben, können Sie mir jederzeit an [email protected] schreiben - ich freue mich auf ein Gespräch mit Ihnen!
- Technisch gesehen ist "interpretiert" vs. "kompiliert" ein Merkmal der Implementierung, nicht der Sprache, aber Python wird sicherlich typischerweise durch einen Interpreter implementiert).
- "Das Latein der Computersprachen": eine tote Sprache, die niemand mehr benutzt, die aber dennoch Studenten in alle wichtigen Merkmale einer Sprache einführt und die Grundlage für viele moderne Sprachen bildet.
- Wenn Sie dieses Wunderwerk genauer erforschen möchten, empfehle ich Ihnen den Kurs nand2tetris, der zeigt, wie einfache Logikgatter zu einem voll funktionsfähigen Computer kombiniert werden können. Das Steam-Spiel Turing Complete verspricht ebenfalls, ein ähnliches Ziel zu erreichen.
- Ich halte mich eng an das Beispiel aus dem Zero2Hero course von George Datseris, dessen übriger Inhalt für diejenigen interessant sein könnte, die eine umfassendere Einführung in Julia wünschen
- Ein "Objekt" ist in den meisten "objektorientierten" Sprachen eine Struktur, die Felder/Attribute (Variablen, die relativ zum Objekt definiert sind) und Prozeduren/Methoden (Funktionen, die relativ zum Objekt definiert sind) enthält.
- Ich empfehle, ein spezielles Modul für Operationen/Erweiterungen zu haben, das Sie immer dann importieren können, wenn Sie Julia schreiben, damit es sich so verhält, wie Sie es wollen, ohne dass Sie darüber nachdenken müssen.
- Die selbst effizient als zwei Zahlen dargestellt werden kann: eine Länge (des Vektors) und ein Index (wenn er nicht Null ist).

Mit einem Experten sprechen








