
15/07/2022
Délimitation des bassins versants à l'aide de Pysheds

Le bassin versant d'une rivière est la limite à l'intérieur de laquelle une goutte d'eau pourrait se déverser dans l'océan au niveau du même estuaire. Plus généralement, un bassin versant peut être défini par un "point de déversement" (l'estuaire dans le cas d'une rivière entière) situé plus en amont, ce qui signifie que si vous interrogez les données pluviométriques dans le bassin versant, vous pouvez prédire des éléments tels que le volume/le débit de l'eau au point de déversement.
Les responsables de décisions dans de nombreux domaines peuvent trouver une application à la délimitation d'un bassin versant. Par exemple, dans le domaine de l'urbanisme, il peut être utile de trouver le bassin versant d'une rivière pour aider à prédire l'étendue des inondations, tandis que dans le domaine de la prévision de l'énergie, les exploitants de centrales hydroélectriques peuvent utiliser le bassin versant pour estimer la fourniture d'énergie. Dans cet article, je montre comment vous pouvez déterminer les bassins versants et les débits pour n'importe quelle masse d'eau en utilisant les données d'élévation à haute résolution de Meteomatics, disponibles par le biais de notre API.
PySheds
La bibliothèque pysheds contient des fonctions/méthodes qui vous permettent de lire des fichiers .tiff et de délimiter des bassins versants. Vous n'avez peut-être pas accès à un fichier .tiff, mais en tant qu'abonné de Meteomatics, vous pouvez utiliser notre API pour obtenir un modèle numérique d'élévation (MNE) et trouver vous-même la limite d'un bassin versant. Je vais vous montrer comment procéder et comment récupérer les données pluviométriques correspondant au bassin versant.
elev = api.query_grid( dt.datetime(2000, 1, 1), 'elevation:m', bounds['north'], bounds['west'], bounds['south'], bounds['east'], res, res, username, password )
Voici la structure de ma demande d'API pour les données d'élévation. Par défaut, les données sont obtenues à partir du modèle SRTM/ASTER de la NASA, qui a une résolution au sol d'environ 90 mètres. Il s'agit du même modèle que nous utilisons pour diminuer l'échelle des sorties des modèles météorologiques à résolution grossière de sorte que les données accessibles par l'intermédiaire de l'API Météomatique soient mises à jour en fonction de la géographie locale d'une demande. `bounds` est un dictionnaire qui contient les coordonnées des bords de la région qui m'intéresse, et `res` est une variable qui détermine la résolution des données à acquérir.
Je recommande une résolution aussi élevée que possible, car plus vous pouvez extraire d'informations sur la pente locale à partir de l'API, plus vous obtiendrez une meilleure image de la ligne de partage des eaux. Cela dit :
a) Certaines rivières ont d'énormes bassins versants qui, à haute résolution, peuvent dépasser le nombre maximal de points de données dans une seule demande API2
b) Une résolution de 0,001 degré correspond à peu près à 100 m ; il est donc inutile de demander des données à une résolution supérieure, puisqu'elles sont plus petites que nos données à échelle réduite
L'objet datetime que je transmets comme premier argument de la requête est arbitraire, puisque nous ne nous attendons pas à ce que l'altitude change beaucoup au fil du temps.
Ensuite, je remplace tous les emplacements où l'altitude est égale à zéro par NaN et je transforme les données que j'ai extraites de l'API en un format netCDF (un format standard de l'industrie, nécessaire pour l'étape suivante). Étant donné que l'élévation de 0 m pourrait être exprimée de manière équivalente comme "au niveau de la mer", cela supprime essentiellement l'océan de nos données. C'est important, car sinon l'eau pourrait s'écouler indéfiniment sur cette surface parfaitement plate, ce qui n'est manifestement pas physique.
elev[elev <= 0.0] = np.nan da = elev.T.unstack().to_xarray() nc = da.to_dataset(name='elevation')
Maintenant que nous avons un netCDF d'élévation, nous devons installer le paquet rioxarray. Ce package fonctionne avec xarray (un package pour manipuler les données netCDF que vous devriez également installer) pour faciliter l'écriture de fichiers TIFF. Après avoir installé ces packages à l'aide de la commande
`pip install -c conda-forge <package>`
vous pouvez mettre en œuvre ce qui suit :
nc.rio.set_spatial_dims( 'lon', 'lat', inplace=True)
nc.rio.set_crs("epsg:4326", inplace=True)
nc.rio.to_raster('elevation.tif')
grid = pysheds.grid.Grid.from_raster('elevation.tif')
dem = grid.read_raster('elevation.tif')
Vous obtenez ainsi un modèle numérique d'élévation dans le format souhaité par pysheds. Jetons un coup d'œil à notre MNE.


Nous sommes maintenant presque prêts à délimiter une ligne de partage des eaux. Mais avant cela, nous devons nous occuper des petits artefacts qui peuvent exister dans notre MNE. Pysheds désigne ces artefacts comme des fosses et des dépressions, c'est-à-dire des endroits où la zone environnante est plus élevée que l'artefact (l'eau peut donc s'y accumuler), et des plaines, c'est-à-dire des zones d'élévation constante. Nous avons déjà supprimé la zone plane la plus difficile (et la plus irréaliste), à savoir la mer. Nous pouvons supprimer les autres, ainsi que les fosses et les dépressions, très facilement en utilisant les méthodes suivantes sur l'objet DEM :
dem = grid.fill_pits(dem) dem = grid.fill_depressions(dem) dem = grid.resolve_flats(dem)
Nous devons maintenant vérifier que nous avons bien supprimé tous les artefacts comme décrit ci-dessus
assert not grid.detect_pits(dem).any() assert not grid.detect_depressions(dem).any() assert not grid.detect_flats(dem).any()
Si vous obtenez des erreurs d'assertion, c'est que quelque chose n'a pas fonctionné. J'ai constaté que toutes ces erreurs disparaissaient après avoir correctement masqué l'océan de mes données, mais si les erreurs persistent, vous devrez examiner le MNE en détail pour voir où les choses se passent mal. Heureusement, l'échec de ces assertions ne nous empêche pas de calculer les étapes suivantes, et les résultats de celles-ci peuvent être utiles pour essayer d'analyser l'origine de l'erreur.
Nous pouvons maintenant calculer la direction de l'écoulement et l'accumulation du MNE comme suit :
fdir = grid.flowdir(dem) acc = grid.accumulation(fdir)
La direction de l'écoulement est un nombre compris entre 0 et 360 représentant la direction de l'écoulement du bassin versant à chaque point donné. L'accumulation quantifie les cellules du MNE qui sont en amont de la cellule en question. Cette propriété est utile à connaître pour plusieurs raisons, comme nous le verrons. Le code ci-dessous génère une carte des rivières de notre MNE, que je présente dans la figure 2.
f = plt.figure()
ax = f.add_subplot(111)
f.patch.set_alpha(0)
im = ax.pcolormesh(
nc.lon, nc.lat, masked_acc, zorder=2,
cmap='cubehelix', norm=colors.LogNorm(1, acc.max())
)
plt.colorbar(im, ax=ax, label='Upstream Cells')
plt.title(
f'Flow Accumulation in catchment\n of pour point at {x_snap},{y_snap}',
size=14
)
plt.tight_layout()
plt.show()
Vous pouvez voir que les cellules situées sur les pentes des vallées ont très peu de cellules en amont - presque rien ne coule vers elles - alors que l'accumulation des rivières augmente à mesure qu'elles coulent vers la côte - chaque cellule en aval est alimentée par au moins une cellule en amont. Cela signifie que nous pouvons utiliser l'accumulation comme indicateur de la distance en aval, et que nous pouvons également fixer une valeur raisonnable de l'accumulation pour distinguer les rivières qui coulent des flancs de colline.


Vous pouvez constater que, comme nous l'avons vu précédemment, nos rivières ne savent pas vraiment comment se comporter lorsqu'elles atteignent l'océan. Cela n'a pas d'importance, puisque le débit n'est pas quantifié ici et que nous pouvons simplement masquer ces parties du domaine.
Il est maintenant facile de délimiter le bassin versant d'une rivière. Nous avons simplement besoin des coordonnées du "point de déversement". Il peut s'agir du point où la rivière se jette dans la mer, ou d'un point plus en amont qui vous intéresse. Pour mon exemple à Montpellier, je m'intéresse à l'endroit où le Lez et la Mosson se rejoignent. Ce point se situe à environ 3,81, 43,56. Nous entrons la coordonnée dans notre code, mais nous nous assurons également que nous nous accrochons à un point proche avec suffisamment d'accumulation : il serait embarrassant que le résultat de l'étape suivante nous montre une zone minuscule parce que nous avons accidentellement choisi un flanc de colline à proximité au lieu d'un point dans la rivière...
# Specify pour point x, y = 3.8095, 43.5588 # Snap pour point to high accumulation cell x_snap, y_snap = grid.snap_to_mask(acc > 10000, (x, y)) catch = grid.catchment(x=x_snap, y=y_snap, fdir=fdir, xytype='coordinate') masked_acc = np.ma.masked_array(acc, catch==False)
Nous trouvons ensuite le bassin versant à l'aide de la méthode catch de l'objet grille. Il s'agit d'un champ booléen décrivant si une cellule se trouve ou non dans le bassin versant. Je masque mon accumulation en fonction du bassin versant et je montre le résultat ci-dessous

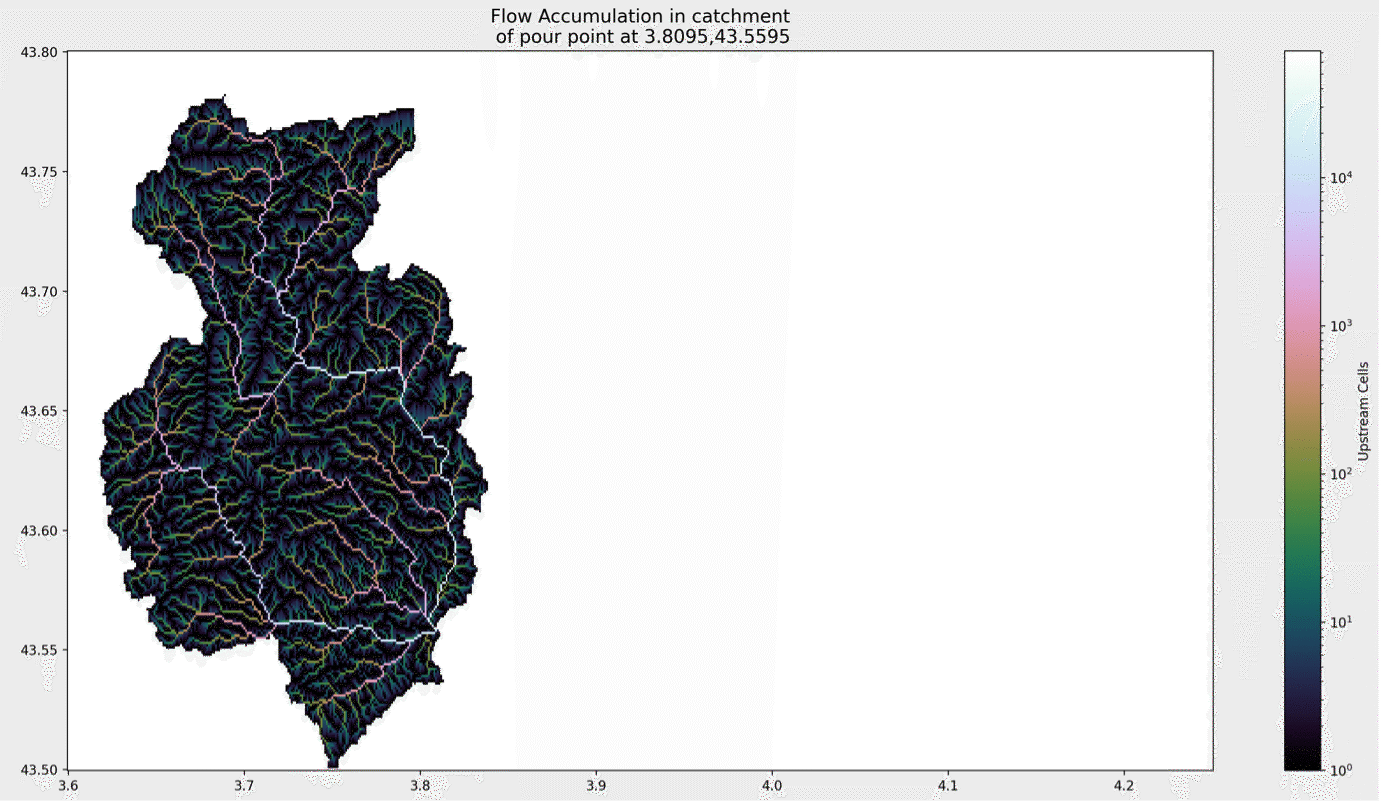
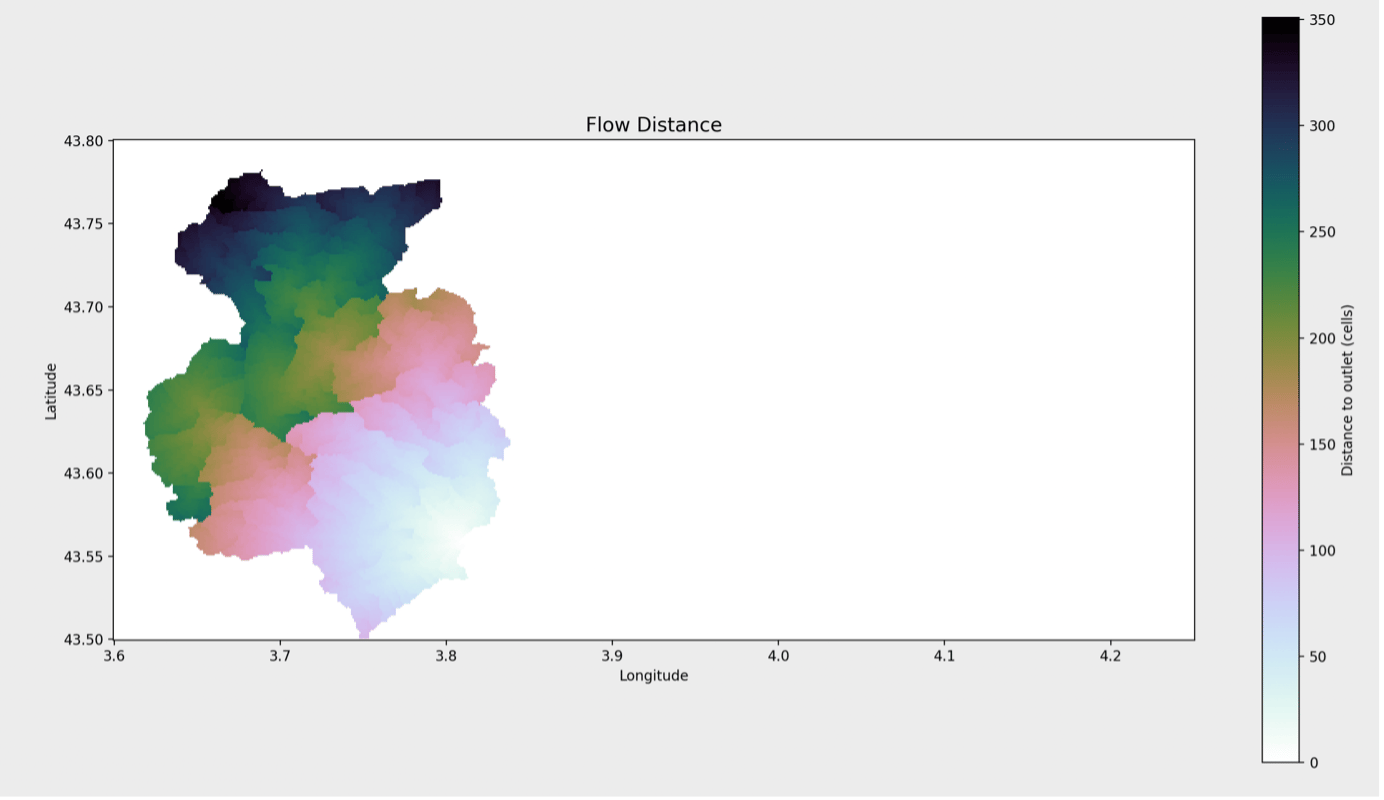
À partir de là, il est assez facile de classer la zone en fonction de la distance qui la sépare du point de déversement
dist = grid.distance_to_outlet( x=x_snap, y=y_snap, fdir=fdir, xytype='coordinate' )

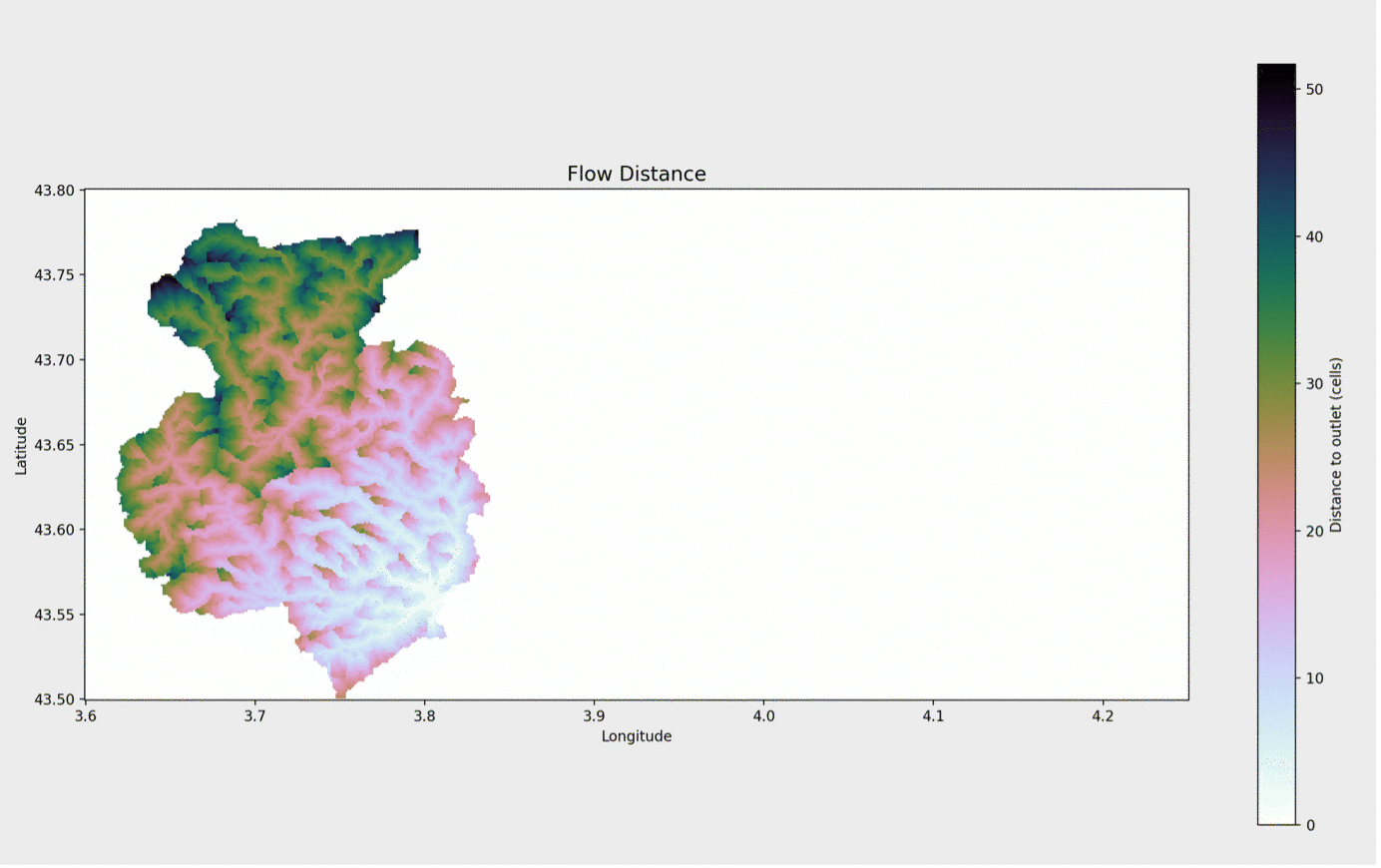
et il n'en faut pas plus pour classer la région en fonction du temps qu'il faudrait à l'eau de chaque cellule pour atteindre le point d'écoulement. Tout ce que nous avons à faire, c'est de mettre en œuvre une hypothèse simple - par exemple, que l'eau d'une rivière (c'est-à-dire une cellule avec beaucoup de cellules en amont) s'écoule environ 10 fois plus vite que l'eau sur une pente
weights = acc.copy() weights[acc >= 100] = 0.1 weights[(0 < acc) & (acc < 100)] = 1.

Le paquet pysheds est potentiellement très utile pour toute application liée aux niveaux et aux débits des rivières. Certaines de ces applications sont montrées ou décrites dans cet article, mais il y en a beaucoup d'autres prêtes à être exploitées par les utilisateurs ayant accès à un MNE de haute qualité tel que celui fourni aux abonnés de l'API de Meteomatics.
Vous pouvez trouver des informations sur nos données géographiques supplémentaires ici. Comme d'habitude, si vous avez des questions sur l'utilisation de nos données ou sur les techniques explorées dans cet article, n'hésitez pas à me contacter en utilisant le formulaire ci-dessous !
- Vous pouvez contourner ce problème en combinant plusieurs demandes après le téléchargement à partir de l'API.

Parlez à un expert









